NYTimes Article Search API
I don’t have much to add that the New York Times hasn’t already said about their Article Search API. Its an amazing corpus to be searchable, both in breadth, and scope, and for sheer richness of the classification. I can’t think of an remotely comparable dataset with such a rich API.
Couple of things I noticed that I wanted to call out.
Get info about an article/Search by URL
Positioned as a search API, it also doubles as a “getInfo”-style API, as article URL is one of the searchable fields.
?query=url:$article_url
Just make sure to remove the various query string bits that the Times appends, as these aren’t indexed. Should make a “find the history of this topic being discussed” Greasemonkey script a snap.
Expert’s attention information
One of my less comprehensible requests to the NYTimes developer team at OSCON last year was to make sure their APIs exposed the “attention information of [their] editors.” Age of amateur, citizen journalism, and radical decentralization are all awesome, but the NYTimes’ editors job is to think about what is important and interesting full time; and that’s information worth mining.
And they did!
The page_facet, and nytd_section_facet both allow you to gauge some degree of relative weight given to a story. (section_page_facet seems like it ought to do the same thing, but I couldn’t get it to work)
?query=flickr nytd_section_facet:[Front Page]
Gives you articles mentioning “flickr” featured on the NYTimes front page. (of which it only finds 3, alas)
API Design
Good stuff:
- Clean hackable URLs, you can play with it in your browser and see what you’re going to get.
- The getList + extras (called fields in the NYTimes API) is the house wisdom at Flickr, and I’m glad to see it elsewhere
- The parsed tokens block is neat, and I can see it being incredibly useful for working with such a large, varied corpus
- The sure amount of searchable/indexable metadata and the granularity is really unprecedented, great to see them go out with such a rich, “here’s the data do something great” approach.
Visualizations
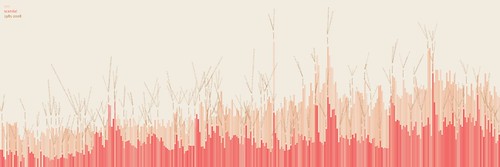
The graphic at the top of this blog post is a “visualization of the frequency of occurrence of the words ‘sex’ and ‘scandal’ in the New York Times, since 1981.”, part of a [set of visualizations by blprnt*van](http://flickr.com/photos/blprnt/sets/72157613381549987/) built with the article search API, and Processing.